2.5. Red Hat Enterprise Linux-Specific Information
Red Hat Enterprise Linux comes with a variety of resource monitoring tools. While there are more than those listed here, these tools are representative in terms of functionality. The tools are:
free
top (and GNOME System Monitor, a more graphically oriented version of top)
vmstat
The Sysstat suite of resource monitoring tools
The OProfile system-wide profiler
Let us examine each one in more detail.
2.5.1. free
The free command displays system memory utilization. Here is an example of its output:
total used free shared buffers cached Mem: 255508 240268 15240 0 7592 86188 -/+ buffers/cache: 146488 109020 Swap: 530136 26268 503868 |
The Mem: row displays physical memory utilization, while the Swap: row displays the utilization of the system swap space, and the -/+ buffers/cache: row displays the amount of physical memory currently devoted to system buffers.
Since free by default only displays memory utilization information once, it is only useful for very short-term monitoring, or quickly determining if a memory-related problem is currently in progress. Although free has the ability to repetitively display memory utilization figures via its -s option, the output scrolls, making it difficult to easily detect changes in memory utilization.
 | Tip | ||
|---|---|---|---|
A better solution than using free -s would be to run free using the watch command. For example, to display memory utilization every two seconds (the default display interval for watch), use this command:
The watch command issues the free command every two seconds, updating by clearing the screen and writing the new output to the same screen location. This makes it much easier to determine how memory utilization changes over time, since watch creates a single updated view with no scrolling. You can control the delay between updates by using the -n option, and can cause any changes between updates to be highlighted by using the -d option, as in the following command:
For more information, refer to the watch man page. The watch command runs until interrupted
with |
2.5.2. top
While free displays only memory-related information, the top command does a little bit of everything. CPU utilization, process statistics, memory utilization — top monitors it all. In addition, unlike the free command, top's default behavior is to run continuously; there is no need to use the watch command. Here is a sample display:
14:06:32 up 4 days, 21:20, 4 users, load average: 0.00, 0.00, 0.00
77 processes: 76 sleeping, 1 running, 0 zombie, 0 stopped
CPU states: cpu user nice system irq softirq iowait idle
total 19.6% 0.0% 0.0% 0.0% 0.0% 0.0% 180.2%
cpu00 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 100.0%
cpu01 19.6% 0.0% 0.0% 0.0% 0.0% 0.0% 80.3%
Mem: 1028548k av, 716604k used, 311944k free, 0k shrd, 131056k buff
324996k actv, 108692k in_d, 13988k in_c
Swap: 1020116k av, 5276k used, 1014840k free 382228k cached
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND
17578 root 15 0 13456 13M 9020 S 18.5 1.3 26:35 1 rhn-applet-gu
19154 root 20 0 1176 1176 892 R 0.9 0.1 0:00 1 top
1 root 15 0 168 160 108 S 0.0 0.0 0:09 0 init
2 root RT 0 0 0 0 SW 0.0 0.0 0:00 0 migration/0
3 root RT 0 0 0 0 SW 0.0 0.0 0:00 1 migration/1
4 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 keventd
5 root 34 19 0 0 0 SWN 0.0 0.0 0:00 0 ksoftirqd/0
6 root 35 19 0 0 0 SWN 0.0 0.0 0:00 1 ksoftirqd/1
9 root 15 0 0 0 0 SW 0.0 0.0 0:07 1 bdflush
7 root 15 0 0 0 0 SW 0.0 0.0 1:19 0 kswapd
8 root 15 0 0 0 0 SW 0.0 0.0 0:14 1 kscand
10 root 15 0 0 0 0 SW 0.0 0.0 0:03 1 kupdated
11 root 25 0 0 0 0 SW 0.0 0.0 0:00 0 mdrecoveryd |
The display is divided into two sections. The top section
contains information related to overall system status — uptime,
load average, process counts, CPU status, and utilization statistics
for both memory and swap space. The lower section displays
process-level statistics. It is possible to change what is displayed
while top is running. For example,
top by default displays both idle and non-idle
processes. To display only non-idle processes, press
 | Warning |
|---|---|
Although top appears like a simple
display-only program, this is not the case. That is because
top uses single character commands to perform
various operations. For example, if you are logged in as root, it
is possible to change the priority and even kill any process on your
system. Therefore, until you have reviewed top's
help screen (type |
2.5.2.1. The GNOME System Monitor — A Graphical top
If you are more comfortable with graphical user interfaces, the GNOME System Monitor may be more to your liking. Like top, the GNOME System Monitor displays information related to overall system status, process counts, memory and swap utilization, and process-level statistics.
However, the GNOME System Monitor goes a step further by also including graphical representations of CPU, memory, and swap utilization, along with a tabular disk space utilization listing. An example of the GNOME System Monitor's Process Listing display appears in Figure 2-1.
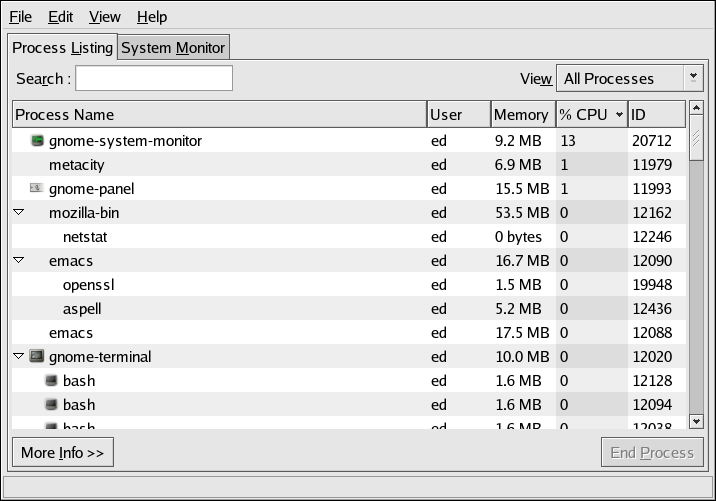
Additional information can be displayed for a specific process by first clicking on the desired process and then clicking on the More Info button.
To display the CPU, memory, and disk usage statistics, click on the System Monitor tab.
2.5.3. vmstat
For a more concise understanding of system performance, try vmstat. With vmstat, it is possible to get an overview of process, memory, swap, I/O, system, and CPU activity in one line of numbers:
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 5276 315000 130744 380184 1 1 2 24 14 50 1 1 47 0
|
The first line divides the fields in six categories, including process, memory, swap, I/O, system, and CPU related statistics. The second line further identifies the contents of each field, making it easy to quickly scan data for specific statistics.
The process-related fields are:
r — The number of runnable processes waiting for access to the CPU
b — The number of processes in an uninterruptible sleep state
The memory-related fields are:
swpd — The amount of virtual memory used
free — The amount of free memory
buff — The amount of memory used for buffers
cache — The amount of memory used as page cache
The swap-related fields are:
si — The amount of memory swapped in from disk
so — The amount of memory swapped out to disk
The I/O-related fields are:
bi — Blocks sent to a block device
bo — Blocks received from a block device
The system-related fields are:
in — The number of interrupts per second
cs — The number of context switches per second
The CPU-related fields are:
us — The percentage of the time the CPU ran user-level code
sy — The percentage of the time the CPU ran system-level code
id — The percentage of the time the CPU was idle
wa — I/O wait
When vmstat is run without any options, only one line is displayed. This line contains averages, calculated from the time the system was last booted.
However, most system administrators do not rely on the data in this line, as the time over which it was collected varies. Instead, most administrators take advantage of vmstat's ability to repetitively display resource utilization data at set intervals. For example, the command vmstat 1 displays one new line of utilization data every second, while the command vmstat 1 10 displays one new line per second, but only for the next ten seconds.
In the hands of an experienced administrator, vmstat can be used to quickly determine resource utilization and performance issues. But to gain more insight into those issues, a different kind of tool is required — a tool capable of more in-depth data collection and analysis.
2.5.4. The Sysstat Suite of Resource Monitoring Tools
While the previous tools may be helpful for gaining more insight into system performance over very short time frames, they are of little use beyond providing a snapshot of system resource utilization. In addition, there are aspects of system performance that cannot be easily monitored using such simplistic tools.
Therefore, a more sophisticated tool is necessary. Sysstat is such a tool.
Sysstat contains the following tools related to collecting I/O and CPU statistics:
- iostat
Displays an overview of CPU utilization, along with I/O statistics for one or more disk drives.
- mpstat
Displays more in-depth CPU statistics.
Sysstat also contains tools that collect system resource utilization data and create daily reports based on that data. These tools are:
- sadc
Known as the system activity data collector, sadc collects system resource utilization information and writes it to a file.
- sar
Producing reports from the files created by sadc, sar reports can be generated interactively or written to a file for more intensive analysis.
The following sections explore each of these tools in more detail.
2.5.4.1. The iostat command
The iostat command at its most basic provides an overview of CPU and disk I/O statistics:
Linux 2.4.20-1.1931.2.231.2.10.ent (pigdog.example.com) 07/11/2003
avg-cpu: %user %nice %sys %idle
6.11 2.56 2.15 89.18
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
dev3-0 1.68 15.69 22.42 31175836 44543290
|
Below the first line (which contains the system's kernel version and hostname, along with the current date), iostat displays an overview of the system's average CPU utilization since the last reboot. The CPU utilization report includes the following percentages:
Percentage of time spent in user mode (running applications, etc.)
Percentage of time spent in user mode (for processes that have altered their scheduling priority using nice(2))
Percentage of time spent in kernel mode
Percentage of time spent idle
Below the CPU utilization report is the device utilization report. This report contains one line for each active disk device on the system and includes the following information:
The device specification, displayed as dev<major-number>-sequence-number, where <major-number> is the device's major number[1], and <sequence-number> is a sequence number starting at zero.
The number of transfers (or I/O operations) per second.
The number of 512-byte blocks read per second.
The number of 512-byte blocks written per second.
The total number of 512-byte blocks read.
The total number of 512-byte block written.
This is just a sample of the information that can be obtained using iostat. For more information, refer to the iostat(1) man page.
2.5.4.2. The mpstat command
The mpstat command at first appears no different from the CPU utilization report produced by iostat:
Linux 2.4.20-1.1931.2.231.2.10.ent (pigdog.example.com) 07/11/2003
07:09:26 PM CPU %user %nice %system %idle intr/s
07:09:26 PM all 6.40 5.84 3.29 84.47 542.47
|
With the exception of an additional column showing the interrupts per second being handled by the CPU, there is no real difference. However, the situation changes if mpstat's -P ALL option is used:
Linux 2.4.20-1.1931.2.231.2.10.ent (pigdog.example.com) 07/11/2003
07:13:03 PM CPU %user %nice %system %idle intr/s
07:13:03 PM all 6.40 5.84 3.29 84.47 542.47
07:13:03 PM 0 6.36 5.80 3.29 84.54 542.47
07:13:03 PM 1 6.43 5.87 3.29 84.40 542.47
|
On multiprocessor systems, mpstat allows the utilization for each CPU to be displayed individually, making it possible to determine how effectively each CPU is being used.
2.5.4.3. The sadc command
As stated earlier, the sadc command collects system utilization data and writes it to a file for later analysis. By default, the data is written to files in the /var/log/sa/ directory. The files are named sa<dd>, where <dd> is the current day's two-digit date.
sadc is normally run by the sa1 script. This script is periodically invoked by cron via the file sysstat, which is located in /etc/cron.d/. The sa1 script invokes sadc for a single one-second measuring interval. By default, cron runs sa1 every 10 minutes, adding the data collected during each interval to the current /var/log/sa/sa<dd> file.
2.5.4.4. The sar command
The sar command produces system utilization reports based on the data collected by sadc. As configured in Red Hat Enterprise Linux, sar is automatically run to process the files automatically collected by sadc. The report files are written to /var/log/sa/ and are named sar<dd>, where <dd> is the two-digit representations of the previous day's two-digit date.
sar is normally run by the sa2 script. This script is periodically invoked by cron via the file sysstat, which is located in /etc/cron.d/. By default, cron runs sa2 once a day at 23:53, allowing it to produce a report for the entire day's data.
2.5.4.4.1. Reading sar Reports
The format of a sar report produced by the default Red Hat Enterprise Linux configuration consists of multiple sections, with each section containing a specific type of data, ordered by the time of day that the data was collected. Since sadc is configured to perform a one-second measurement interval every ten minutes, the default sar reports contain data in ten-minute increments, from 00:00 to 23:50[2].
Each section of the report starts with a heading describing the data contained in the section. The heading is repeated at regular intervals throughout the section, making it easier to interpret the data while paging through the report. Each section ends with a line containing the average of the data reported in that section.
Here is a sample section sar report, with the data from 00:30 through 23:40 removed to save space:
00:00:01 CPU %user %nice %system %idle
00:10:00 all 6.39 1.96 0.66 90.98
00:20:01 all 1.61 3.16 1.09 94.14
…
23:50:01 all 44.07 0.02 0.77 55.14
Average: all 5.80 4.99 2.87 86.34
|
In this section, CPU utilization information is displayed. This is very similar to the data displayed by iostat.
Other sections may have more than one line's worth of data per time, as shown by this section generated from CPU utilization data collected on a dual-processor system:
00:00:01 CPU %user %nice %system %idle
00:10:00 0 4.19 1.75 0.70 93.37
00:10:00 1 8.59 2.18 0.63 88.60
00:20:01 0 1.87 3.21 1.14 93.78
00:20:01 1 1.35 3.12 1.04 94.49
…
23:50:01 0 42.84 0.03 0.80 56.33
23:50:01 1 45.29 0.01 0.74 53.95
Average: 0 6.00 5.01 2.74 86.25
Average: 1 5.61 4.97 2.99 86.43
|
There are a total of seventeen different sections present in reports generated by the default Red Hat Enterprise Linux sar configuration; some are explored in upcoming chapters. For more information about the data contained in each section, refer to the sar(1) man page.
2.5.5. OProfile
The OProfile system-wide profiler is a low-overhead monitoring tool. OProfile makes use of the processor's performance monitoring hardware[3] to determine the nature of performance-related problems.
Performance monitoring hardware is part of the processor itself. It takes the form of a special counter, incremented each time a certain event (such as the processor not being idle or the requested data not being in cache) occurs. Some processors have more than one such counter and allow the selection of different event types for each counter.
The counters can be loaded with an initial value and produce an interrupt whenever the counter overflows. By loading a counter with different initial values, it is possible to vary the rate at which interrupts are produced. In this way it is possible to control the sample rate and, therefore, the level of detail obtained from the data being collected.
At one extreme, setting the counter so that it generates an overflow interrupt with every event provides extremely detailed performance data (but with massive overhead). At the other extreme, setting the counter so that it generates as few interrupts as possible provides only the most general overview of system performance (with practically no overhead). The secret to effective monitoring is the selection of a sample rate sufficiently high to capture the required data, but not so high as to overload the system with performance monitoring overhead.
| Warning |
|---|---|
You can configure OProfile so that it produces sufficient overhead to render the system unusable. Therefore, you must exercise care when selecting counter values. For this reason, the opcontrol command supports the --list-events option, which displays the event types available for the currently-installed processor, along with suggested minimum counter values for each. |
It is important to keep the tradeoff between sample rate and overhead in mind when using OProfile.
2.5.5.1. OProfile Components
Oprofile consists of the following components:
Data collection software
Data analysis software
Administrative interface software
The data collection software consists of the oprofile.o kernel module, and the oprofiled daemon.
The data analysis software includes the following programs:
- op_time
Displays the number and relative percentages of samples taken for each executable file
- oprofpp
Displays the number and relative percentage of samples taken by either function, individual instruction, or in gprof-style output
- op_to_source
Displays annotated source code and/or assembly listings
- op_visualise
Graphically displays collected data
These programs make it possible to display the collected data in a variety of ways.
The administrative interface software controls all aspects of data collection, from specifying which events are to be monitored to starting and stopping the collection itself. This is done using the opcontrol command.
2.5.5.2. A Sample OProfile Session
This section shows an OProfile monitoring and data analysis session from initial configuration to final data analysis. It is only an introductory overview; for more detailed information, consult the Red Hat Enterprise Linux System Administration Guide.
Use opcontrol to configure the type of data to be collected with the following command:
opcontrol \
--vmlinux=/boot/vmlinux-`uname -r` \
--ctr0-event=CPU_CLK_UNHALTED \
--ctr0-count=6000 |
The options used here direct opcontrol to:
Direct OProfile to a copy of the currently running kernel (--vmlinux=/boot/vmlinux-`uname -r`)
Specify that the processor's counter 0 is to be used and that the event to be monitored is the time when the CPU is executing instructions (--ctr0-event=CPU_CLK_UNHALTED)
Specify that OProfile is to collect samples every 6000th time the specified event occurs (--ctr0-count=6000)
Next, check that the oprofile kernel module is loaded by using the lsmod command:
Module Size Used by Not tainted oprofile 75616 1 … |
Confirm that the OProfile file system (located in /dev/oprofile/) is mounted with the ls /dev/oprofile/ command:
0 buffer buffer_watershed cpu_type enable stats 1 buffer_size cpu_buffer_size dump kernel_only |
(The exact number of files varies according to processor type.)
At this point, the /root/.oprofile/daemonrc file contains the settings required by the data collection software:
CTR_EVENT[0]=CPU_CLK_UNHALTED CTR_COUNT[0]=6000 CTR_KERNEL[0]=1 CTR_USER[0]=1 CTR_UM[0]=0 CTR_EVENT_VAL[0]=121 CTR_EVENT[1]= CTR_COUNT[1]= CTR_KERNEL[1]=1 CTR_USER[1]=1 CTR_UM[1]=0 CTR_EVENT_VAL[1]= one_enabled=1 SEPARATE_LIB_SAMPLES=0 SEPARATE_KERNEL_SAMPLES=0 VMLINUX=/boot/vmlinux-2.4.21-1.1931.2.349.2.2.entsmp |
Next, use opcontrol to actually start data collection with the opcontrol --start command:
Using log file /var/lib/oprofile/oprofiled.log Daemon started. Profiler running. |
Verify that the oprofiled daemon is running with the command ps x | grep -i oprofiled:
32019 ? S 0:00 /usr/bin/oprofiled --separate-lib-samples=0 … 32021 pts/0 S 0:00 grep -i oprofiled |
(The actual oprofiled command line displayed by ps is much longer; however, it has been truncated here for formatting purposes.)
The system is now being monitored, with the data collected for all executables present on the system. The data is stored in the /var/lib/oprofile/samples/ directory. The files in this directory follow a somewhat unusual naming convention. Here is an example:
}usr}bin}less#0 |
The naming convention uses the absolute path of each file containing executable code, with the slash (/) characters replaced by right curly brackets (}), and ending with a pound sign (#) followed by a number (in this case, 0.) Therefore, the file used in this example represents data collected while /usr/bin/less was running.
Once data has been collected, use one of the analysis tools to display it. One nice feature of OProfile is that it is not necessary to stop data collection before performing a data analysis. However, you must wait for at least one set of samples to be written to disk, or use the opcontrol --dump command to force the samples to disk.
In the following example, op_time is used to display (in reverse order — from highest number of samples to lowest) the samples that have been collected:
3321080 48.8021 0.0000 /boot/vmlinux-2.4.21-1.1931.2.349.2.2.entsmp 761776 11.1940 0.0000 /usr/bin/oprofiled 368933 5.4213 0.0000 /lib/tls/libc-2.3.2.so 293570 4.3139 0.0000 /usr/lib/libgobject-2.0.so.0.200.2 205231 3.0158 0.0000 /usr/lib/libgdk-x11-2.0.so.0.200.2 167575 2.4625 0.0000 /usr/lib/libglib-2.0.so.0.200.2 123095 1.8088 0.0000 /lib/libcrypto.so.0.9.7a 105677 1.5529 0.0000 /usr/X11R6/bin/XFree86 … |
Using less is a good idea when producing a report interactively, as the reports can be hundreds of lines long. The example given here has been truncated for that reason.
The format for this particular report is that one line is produced for each executable file for which samples were taken. Each line follows this format:
<sample-count> <sample-percent> <unused-field> <executable-name> |
Where:
<sample-count> represents the number of samples collected
<sample-percent> represents the percentage of all samples collected for this specific executable
<unused-field> is a field that is not used
<executable-name> represents the name of the file containing executable code for which samples were collected.
This report (produced on a mostly-idle system) shows that nearly half of all samples were taken while the CPU was running code within the kernel itself. Next in line was the OProfile data collection daemon, followed by a variety of libraries and the X Window System server, XFree86. It is worth noting that for the system running this sample session, the counter value of 6000 used represents the minimum value recommended by opcontrol --list-events. This means that — at least for this particular system — OProfile overhead at its highest consumes roughly 11% of the CPU.